
原文地址:https://yuzi.dev/posts/frontend/stream-upload
书接上回,直接整个文件整存整取对于小文件来说还好,如果是几 G 的大文件,对内存的占用不能不忽视了。所以我们应该借鉴流式传输的思想,每一次只处理一块,处理完就丢出去(丢给下一步,或最终写入硬盘),这样同一个时刻只会占用服务器的小部分内存,减轻了服务器的压力。
浏览器端拆分
首先,我们在浏览器端就可以完成文件的读取,file.stream().getReader()就可以帮助我们简单的完成流式读取。其简单用法如下:
customRequest={async ({ file }) => {
if (file instanceof File) {
const reader = file.stream().getReader()
while (1) {
const { value, done } = await reader.read()
console.log(value, done)
if (done || value === undefined) {
// 读取完成
break
}
//value 即为 Uint8Array 格式的 ArrayBuffer,可以在此发送这个 chunk,直到读取完成
}
}
}}
鉴权问题
流式上传简单地说就是把文件拆成几块分成几次发,但是拆分文件意味着会有几次甚至几十次的请求,如何鉴权呢?总不可能每次都查表吧,那样效率简直低到让人发指。所以我们可以借鉴「缓存」的思想,给一个文件的请求生成一个 Token,存进一个哈希表里,之后的请求就可以让前端带上这个 Token,就可以直接查快速的哈希表了,而不需要再去查数据库,上传完成后在哈希表里删去这个 Token 即可。
基于以上思想,上传一个文件可以分成三部分:第一个 chunk,带上 id、path、name 等信息,next 鉴权后生成 Token 存入哈希表中,并将这个 Token 返回前端->后续上传请求,只带 Token 和 order->上传完成,带上 total,后端完成文件合并并放置在指定位置,删去 token。
可以借助两张草稿理解这个过程(草稿和最终采用的方法并不完全一样,后面会提):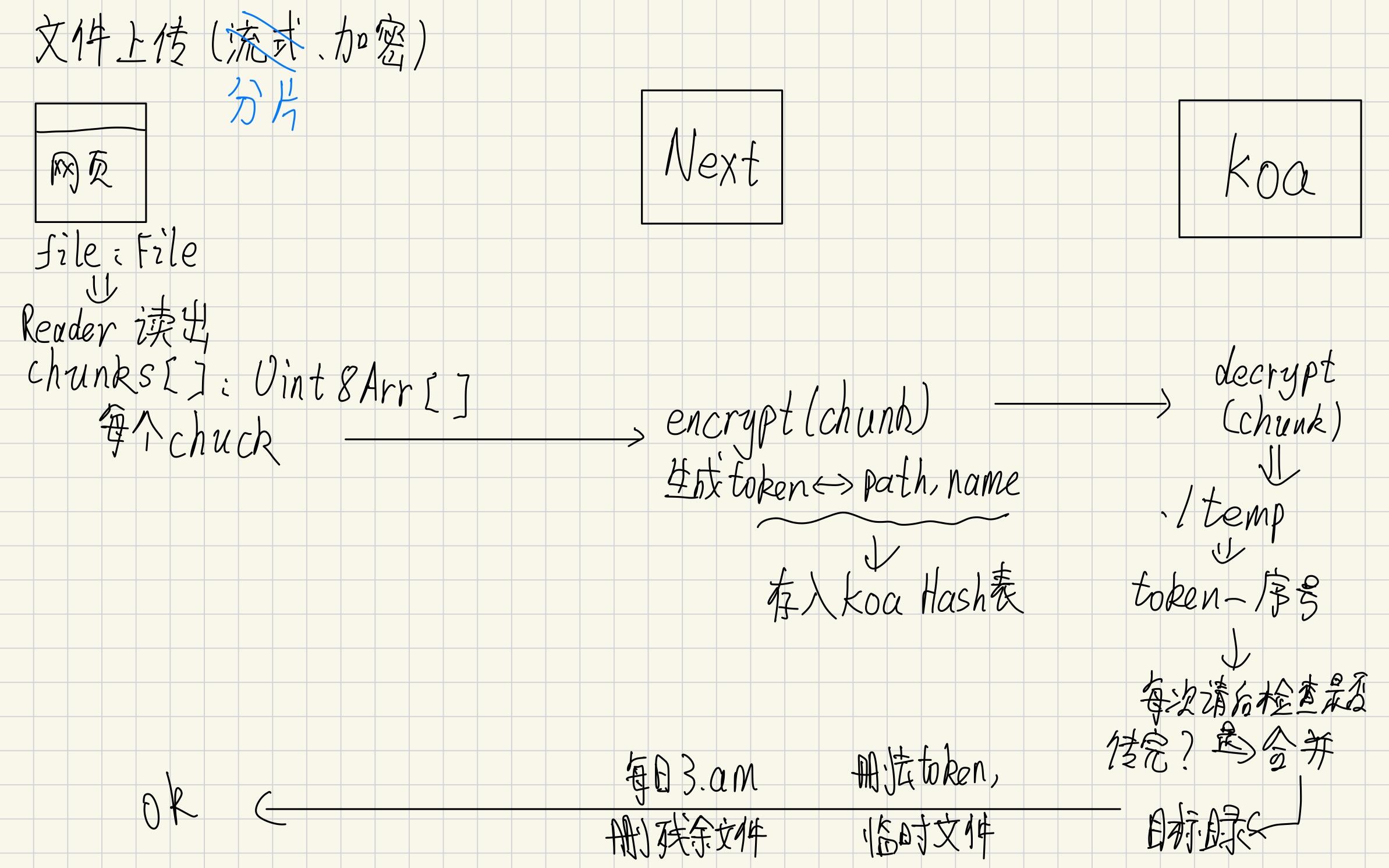

最初的想法是,把这些请求放进 promiseAll 中,resolve 了就代表上传已经完成。但是这样一股脑的发请求会直接卡死服务端,而且请求也会超时造成失败。所以最后采取的方法仍是一个请求一个请求的发,完成后发下一个请求,所以前端可以写成这样:
customRequest={async ({ file }) => {
if (file instanceof File) {
const reader = file.stream().getReader()
let count = 0
let token = ''
while (1) {
const { value, done } = await reader.read()
console.log(value, done)
if (done || value === undefined) {
await uploadFile({ token, total: count - 1 })
message.success('上传成功!')
break
}
if (count === 0) {
const res = await uploadFile(
{ id: instanceId, path, name: file.name },
{ buffer: value, count },
)
if (typeof res != 'string') token = res.token
} else {
console.log(token)
await uploadFile({ token }, { buffer: value, count })
}
count++
}
}
}}
以合适的大小拆分
这样写好后,新的问题产生了,reader 每次读出的 chunk 大小都不一样,从几十 KB 到几 MB 不等,这样一个文件要请求很多很多次,我们可以试着把这个 buffer 攒一下,大一些了再请求,经过我的简单思考,就定在 10MB 吧!
不过 ArrayBuffer 是没有 concat 方法来简单的合并两个 Buffer 的,不过简简单单的 polyfill 一下就行了【也不知道为啥 ES 里没有】
方法来自现代 JS 教程下面的评论,我加上了 TS 和解构,tsc 提示要使用迭代 ArrayBuffer 的特性需要 target 设置为 es2015 以上:
const concatBuffer = (...ArrayOfBuffer: Uint8Array[]) => new Uint8Array(ArrayOfBuffer.flatMap((it) => [...it]))
//用法:
buffer = concatBuffer(bufferA, bufferB,...)
所以我们就可以以每次请求 10MB 的大小拆分文件上传了,经过整理后,最终的前端代码如下:
customRequest={async ({ file }) => {
if (file instanceof File) {
if (files.find((f) => f.name == file.name)) {
// 重名不行
message.error('文件名重复了!')
return
}
setUploadLoading(true)
const reader = file.stream().getReader()
let count = 0
let token = ''
let buffer = new Uint8Array()
const concatBuffer = (...ArrayOfBuffer: Uint8Array[]) =>
new Uint8Array(ArrayOfBuffer.flatMap((it) => [...it]))
while (1) {
const { value, done } = await reader.read()
if (done || value === undefined) {
if (buffer.byteLength) {
//如果还有剩余,上传
await uploadFile({ token }, { buffer, count })
}
await uploadFile({ token, total: count - 1 })
message.success('上传成功!')
// 然后刷新文件列表
setUploadLoading(false)
break
}
if (count === 0) {
const res = await uploadFile(
{ id: instanceId, path, name: file.name },
{ buffer: value, count },
)
if (typeof res != 'string') token = res.token
} else {
buffer = concatBuffer(buffer, value)
if (buffer.byteLength < 1024 * 1024 * 10) {
count-- //本轮不计数
} else {
await uploadFile({ token }, { buffer, count })
buffer = new Uint8Array()
}
}
count++
}
}
}}
Next 后端设置
在前篇,我们已经完成了二进制 buffer 的加解密工作,我们此时就可以直接使用。由于在前端已经拆分好了文件,文件的目标是 Koa,所以 Next 后端只需扮演一个传声筒的角色即可。
const uploadMap = new Map<string, { request: AxiosInstance }>() //Next 的哈希表只需要存向 koa 请求的工具函数即可
export async function POST(req: NextRequest) {
try {
if (req.nextUrl.searchParams.get('path')) {
// 第一次请求上传文件
const { request, instanceID, path } = await verify(req)
const fileName = req.nextUrl.searchParams.get('name')!
const token = crypto.randomBytes(32).toString('hex') //用 node 自己的 crypto 库即可生成一个 32 位的 Token
uploadMap.set(token, {
request,
})
const formData = await req.formData()
const file = formData.get('buffer') as Blob
await request.post('/file/upload', {
path,
id: instanceID,
contentBuffer: await file.arrayBuffer(),
fileName,
token,
})
return response({ data: { token } })
} else if (req.nextUrl.searchParams.get('total')) {
// 上传完成
const token = req.nextUrl.searchParams.get('token')!
const total = Number(req.nextUrl.searchParams.get('total'))
const { request } = uploadMap.get(token)!
await request.post('/file/upload', {
total,
token,
})
return response({ data: 'ok' })
} else if (req.nextUrl.searchParams.get('token')) {
// 后续请求上传文件,token 验证,无需验证权限
const token = req.nextUrl.searchParams.get('token')!
if (!uploadMap.has(token)) throw 'Token invalid.'
const formData = await req.formData()
const file = formData.get('buffer') as Blob
const order = formData.get('count') as string
const { request } = uploadMap.get(token)!
await request.post('/file/upload', {
contentBuffer: await file.arrayBuffer(),
order,
token,
})
return response({ data: 'ok' })
}
} catch (e) {
console.log(e)
return response({ error: typeof e == 'string' ? e : '文件上传失败!' })
}
}
Koa 写入文件配置
因为最开始写的是 PromiseAll 的方案,所以考虑到了乱序到达的问题,给加了 order,现在使用顺序请求的方式其实不需要 order,可以直接在一个文件上 appendFile 最后移动,特此说明。
const uploadMap = new Map<
string,
{ id: string; path: string; name: string; count: number; total: number }
>() //count 和 total 其实已经不再需要了
router.post('/upload', async (ctx) => {
try {
const { path, id, fileName, contentBuffer, token, order, total } = ctx
.request.body as {
path?: string
id?: string
fileName?: string
contentBuffer?: Uint8Array //中间件已经解密处理过了,并转成了 ArrayBuffer
token: string
order: string
total?: number
}
if (!token) throw 'token not found'
if (path && id && fileName && contentBuffer) { //第一次请求,置 token
uploadMap.set(token, { id, path, name: fileName, count: 0, total: -1 })
fs.appendFileSync(
'./data/temp/upload/' + token + '-0',
Buffer.from(contentBuffer),
)
} else if (total !== undefined) { //上传完成,合并文件
const { count, id, path, name } = uploadMap.get(token)!
uploadMap.set(token, { id, path, name, count, total })
fs.readdirSync('./data/temp/upload')
.filter((file) => file.startsWith(token))
.sort((a, b) => parseInt(a.split('-')[1]) - parseInt(b.split('-')[1])) //把分块文件筛选出来排好序
.forEach((file) => {
fs.appendFileSync(
'./data/ContainerData/' + id + path + name,
fs.readFileSync('./data/temp/upload/' + file),
) //塞入目标文件
fs.unlinkSync('./data/temp/upload/' + file) //删去临时分块文件
})
uploadMap.delete(token) //删去哈希表中的 token
} else if (order && contentBuffer) { //中间的请求,通过 token 鉴权
const { count, id, path, name, total } = uploadMap.get(token)!
uploadMap.set(token, { id, path, name, count: count + 1, total })
fs.appendFileSync(
'./data/temp/upload/' + token + '-' + order,
Buffer.from(contentBuffer),
)
}
ctx.body = 'success'
} catch (error) {
ctx.status = 400
ctx.body = {
error,
}
}
})
最后
以上的工作看着虽然简单,但也是结结实实地折腾了一天。经过这番折腾,我对二进制、对流的认识又深入了不少、也对性能优化有了新的理解。
另外,中午我的指导老师邀请小组成员开会,会上我评估了一下未完成的工作,发现有十个甚至九个Feature亟待开发。然而我明天起也必须停止开发转向完善我的开题报告的工作去了。唉,时间紧任务重啊!!